M. Principe de dichotomie, complexité
Objectif
L'objectif de ce petit chapitre et dans un premier temps d'expliquer (ou réviser) le principe de dichotomie, puis dans un deuxième temps de mettre en évidence une technique permettant de déterminer une complexité en utilisant une méthode récurrente.
I. Le principe de la dichotomie
Principe de la dichotomie
La dichotomie est une méthode efficace pour chercher un élément dans un ensemble trié. L'idée est de diviser l'espace de recherche en deux à chaque étape, d'où le nom « di-chotomie » (en deux parties).
II. Fonctionnement de la méthode
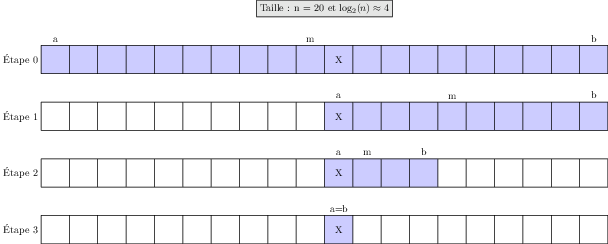
Mettons en évidence sur principe sur l'exemple classique de la recherche d'un élément \(X\) dans un tableau trié \(T\).
Voici les étapes générales :
Fonctionnement méthode dichotomique
-
On prend un tableau trié \(T\) de taille n.
-
On compare l’élément recherché \(X\) avec l’élément du milieu du tableau. Trois cas se présentent :
-
Si \(X\) est égal à l’élément du milieu → trouvé !
-
Si \(X\) est plus petit → on cherche dans la moitié gauche.
-
Si \(X\) est plus grand → on cherche dans la moitié droite.
-
-
On recommence sur la moitié choisie jusqu’à trouver l’élément ou jusqu’à ce que la recherche échoue (tableau vide).
C'est la méthode optimale que l'on utilise pour gagner au « jeu du juste prix ».
Illustration...
Programme en python :
def recherche_dichotomie(L : list, e : int) -> bool :
a,b = 0,len(L)-1 # les indices gauche et droite
while a<=b :
m = (a+b)//2 # division entiere
if e == L[m]:
return True
else :
if e < L[m] :
b = m-1
else:
a = m+1
return False
III. Complexité
1. Méthode de la « récurrence descendante »
Voyons une première méthode pour évaluer la complexité de cet algorithme en fonction de la taille de la liste reçue. On cherche à comptabiliser le nombre de passages dans la boucle while en fonction de la taille n du tableau.
Afin de simplifier les écritures, on va supposer que la taille de la liste reçue est une puissance de 2, c'est à dire: \(n=2^k\). Cela n'est pas un problème, puisque on rappelle que ce qui nous intéresse c'est l'ordre de grandeur du nombre d'opérations lorsque \(n\) devient grand...
Remarquons que l'on a :
Ainsi, pour trouver \(T(n)\) dans le pire des cas, on utiliser la méthode de la récurrence descendante et écrire :
En ajoutant toutes les lignes on obtient \(T(2^k)=T(1)+k=1+k\) et donc \(T(2^k)=O(k)\).
Or puisque \(n=2^k\), on a \(k=\log_2(n)\), d'où l'on déduit :
2. Récurrence classique
On peut aussi faire le raisonnement à l'aide d'un récurrence classique. Montrons que pour tout entier \(k\), la propriété \(P_k : T(2^k)=k+1\) est vraie.
-
Initialisation pour \(k=0\) : On a bien entendu \(T(2^0)=T(1)=1\) (temps constant si le tableau n'a qu'un seul élément)
-
Hérédité : on suppose que pour un certain \(k\), la propriété \(P_k\) est vraie (c'est à dire que \(T(2^k)=k+1\)), et on montre alors que \(P_{k+1}\) est également vraie (c'est à dire que \(T(2^{k+1})=k+2\)).
En effet, si l'on a un tableau de taille \(2^{k+1}\), on commence par passer une fois dans la boucle pour la première étape de l'algorithme. On coupe alors le tableau en deux parties de taille \(2^k\) et on recommence sur l'un des deux sous-tableau. Ainsi :
\[ T(2^{k+1})=1+T(2^k) = k+2 \]C'est que l'on voulait.
-
Conclusion : on a initialisé pour \(k=0\), puis montré l'hérédité, donc la propriété \(P_k\) est vraie pour tout entier \(k\geqslant 0\).
3. Conclusion
Pour savoir si un élément se trouve dans une liste, on vient de voir l'algorithme de recherche dichotomique. Sa complexité est logarithmique (en \(O(\ln(n))\)), ce qui est beaucoup plus performant que l'algorithme déjà rencontré de recherche séquentielle, dont la complexité était linéaire (\(O(n)\)). Cependant, on a besoin que la liste soit triée.
IV. TD : comparaison des algorithmes de recherche séquentielle et dichotomique
Faire le TD M1 :
TD M1 version interactive capytale
Versions html : Énoncé et Correction (à venir)